WhaTap Monitoringは、サービスを構成するサーバーインフラ、アプリ性能をリアルタイムに見える化することで、異常検知と対応にかかる時間・コストを大幅に短縮し、サービスレベル向上に貢献します。障害発生時、インフラの問題か、アプリの問題か、素早く解析可能な統合モニタリング環境を提供します。
WhaTap Monitoringは、クラウドネイティブの分散環境におけるITサービスの稼働状況・性能をリアルタイムに見える化することで、異常検知と対応にかかる時間・労力を大幅に短縮し、サービスレベル向上に貢献します。
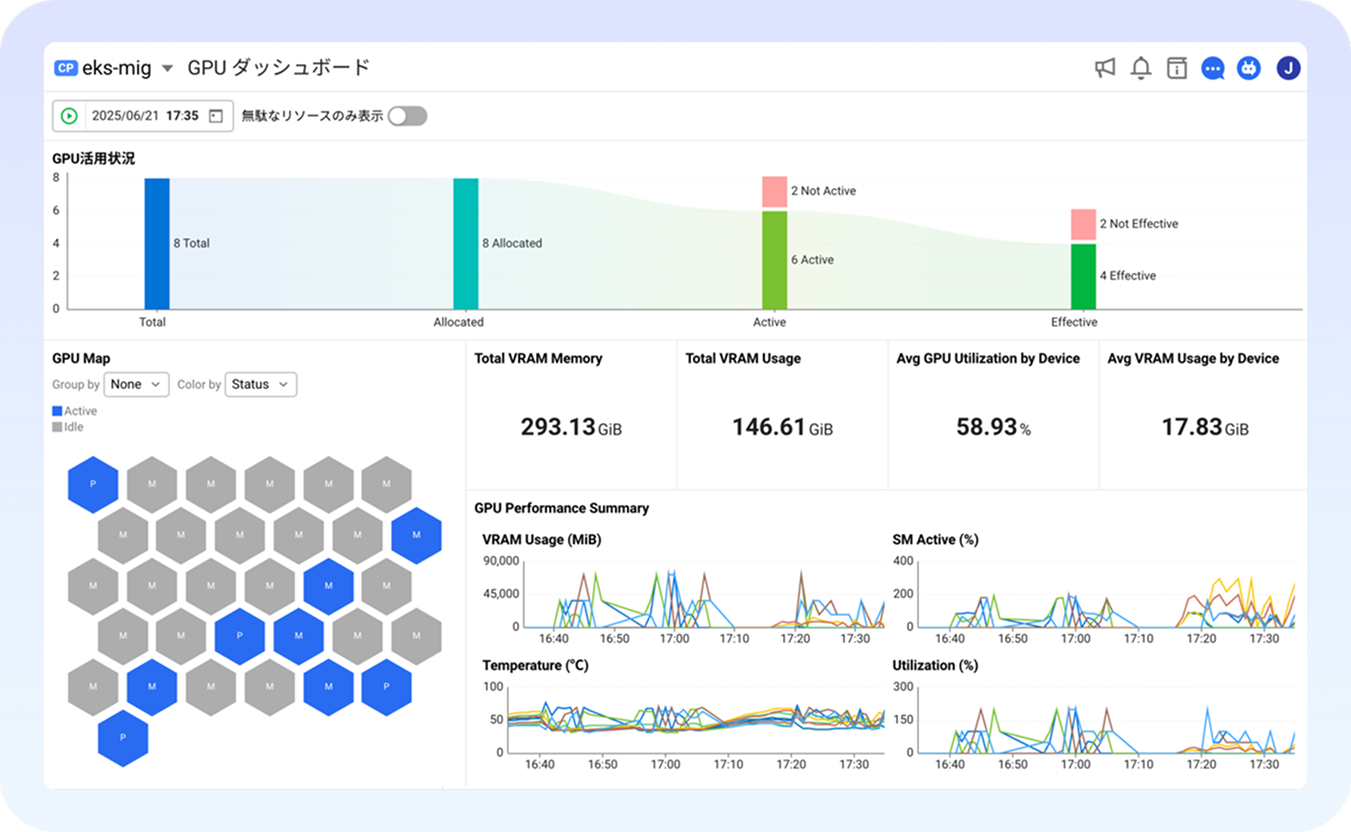
GPUからアプリケーションまで全区間を網羅する統合インサイトを提供します。
AI時代の中核インフラであるGPUは、運用負荷の高いリソース。WhaTapなら、GPUリソース状況が可視化できます。GPUからアプリケーションまで、WhaTapはGPU環境全体を統合的に可視化します。
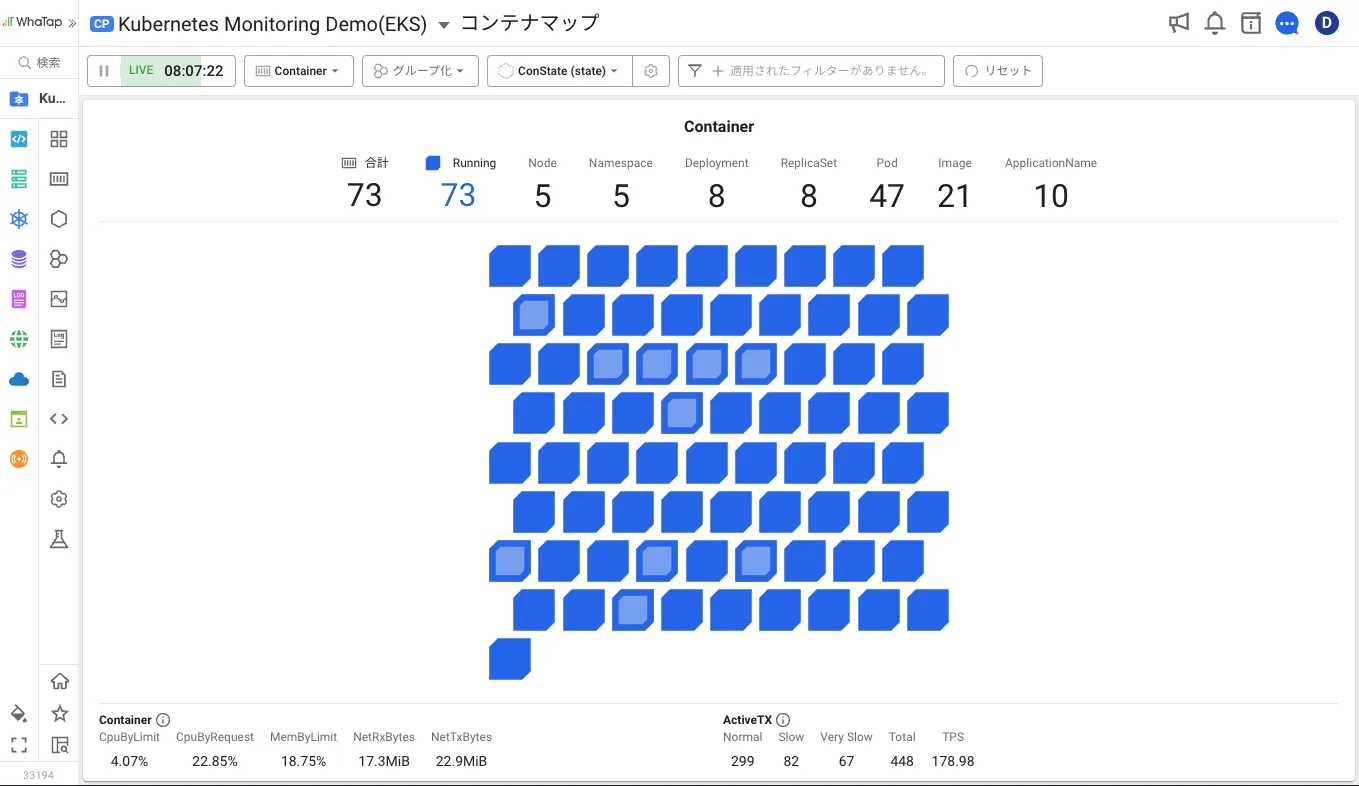
メトリクス、トレース、ログをリアルタイムで収集し、コンテナマップから問題の原因を迅速かつ正確に分析します。EKS、AKS、GKE、OKE、OpenShift、Cocktail、Accordion、PaaS-TAなどのコンテナ環境に対応。
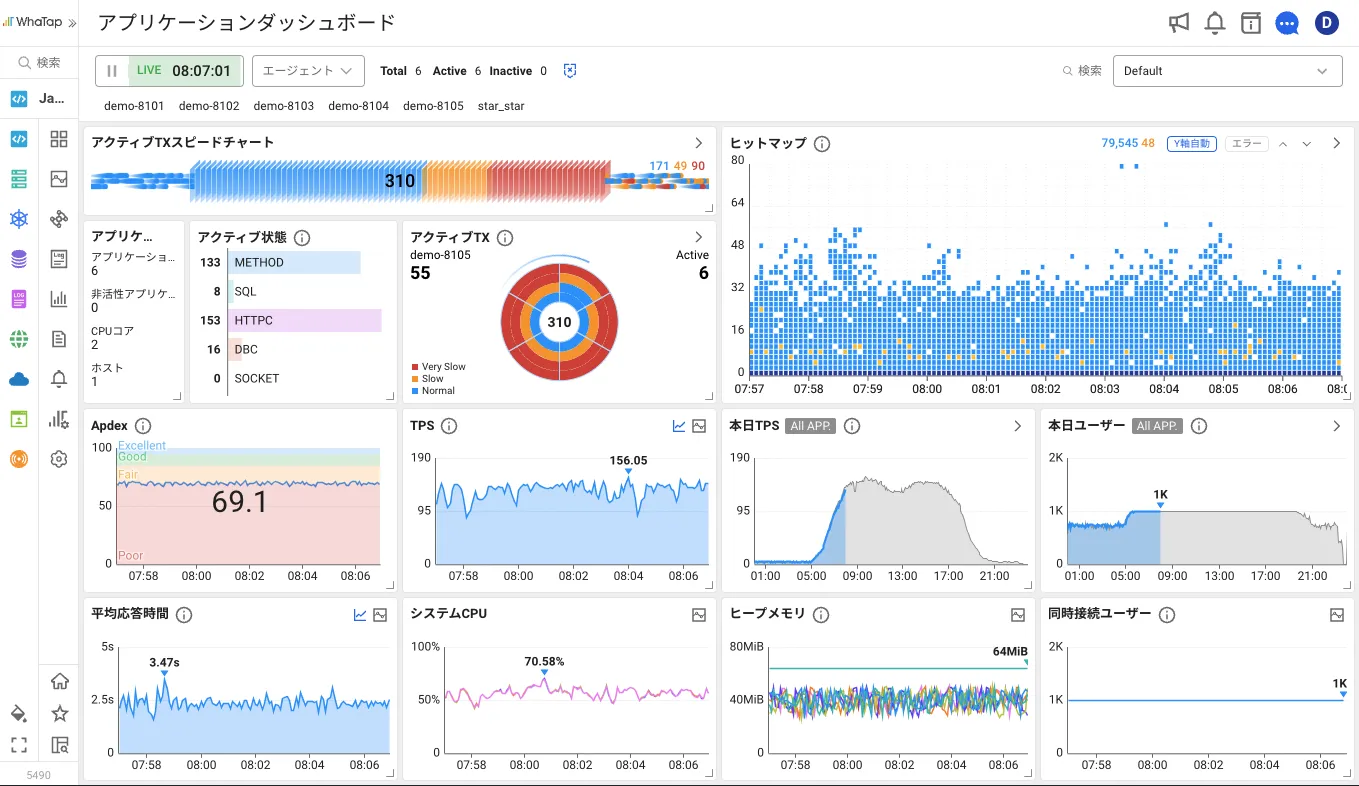
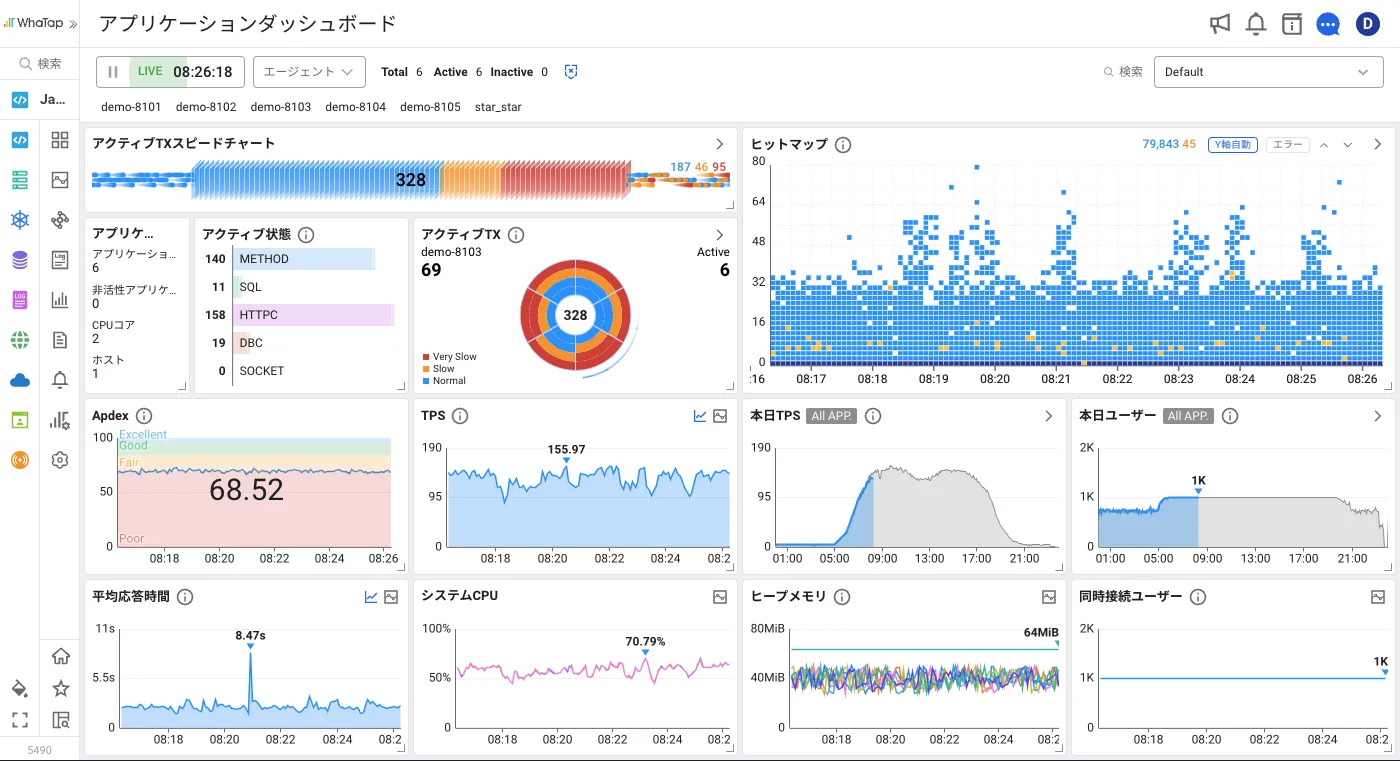
リアルタイムでアプリケーションの性能指標を見える化し、障害をすぐ検知でき、再現待ちや追加情報収集なく、そのまま原因調査が可能です。Java、Node.js、PHP、Python、.NET、Golangに対応。
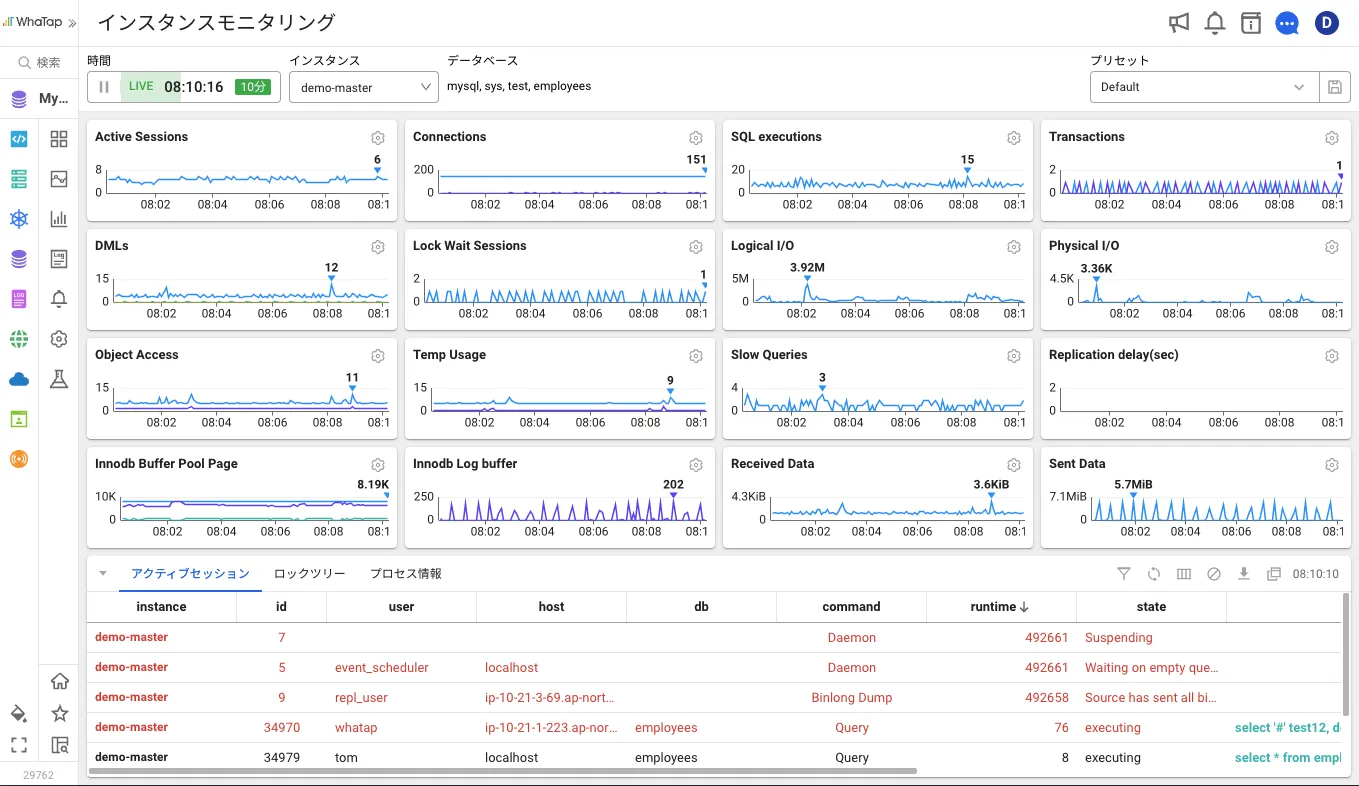
専用サーバーとクラウド上の多様なDBMSを、まとめてモニタリングおよび分析でき、サービスの可用性とパフォーマンスをリアルタイムで管理できます。Oracle、PostgreSQL、MySQL、MariaDB、Redis、MongoDB、MS SQL、AWS RDSなど対応。
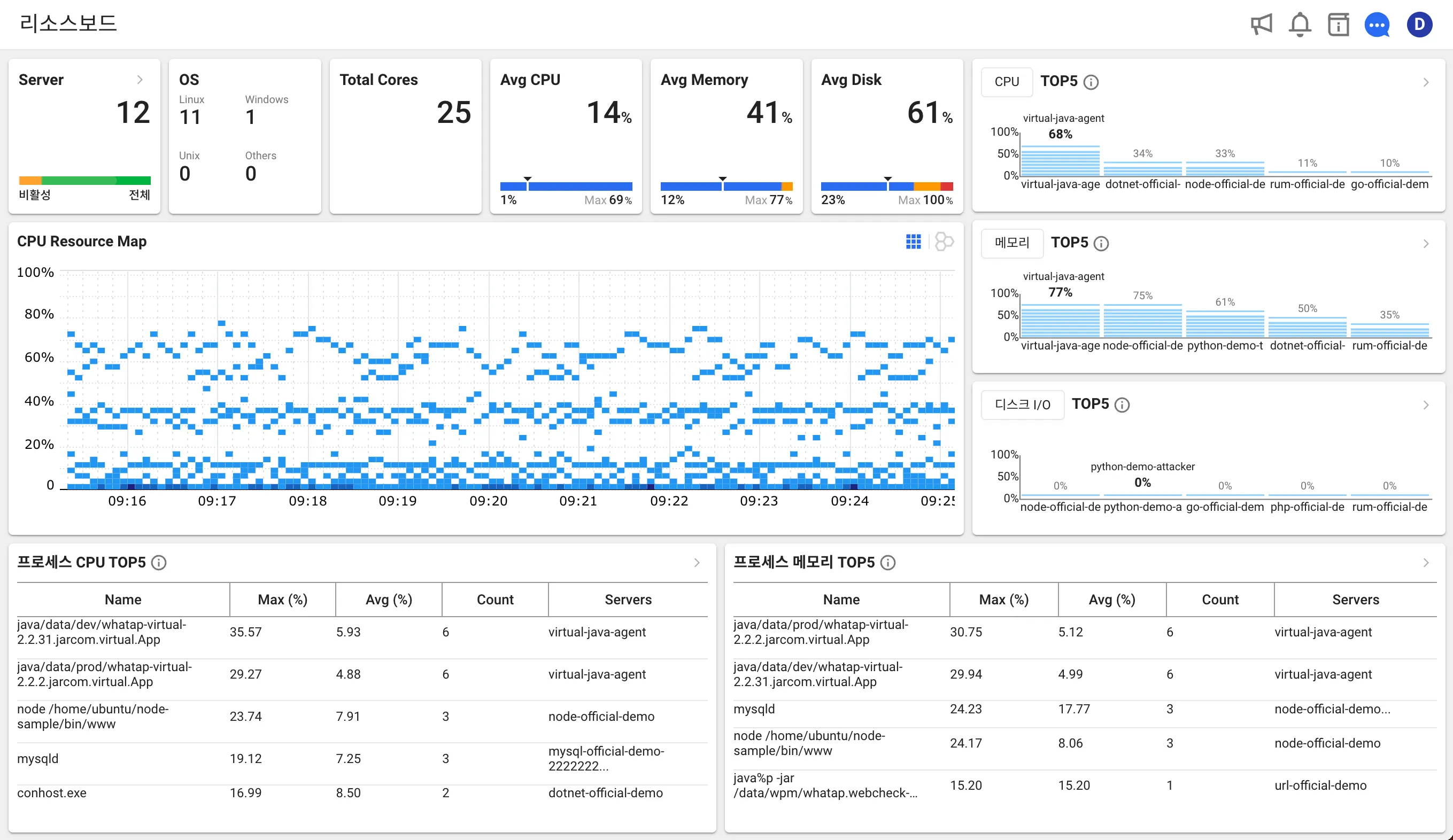
物理、仮想、クラウドのサーバーをまとめてひと目でモニタリングでき、システム全体の状況をリアルタイムで簡単かつ便利に管理できます。x86ベースのWindows、Linux、UNIX(FreeBSD)に対応。
Javaアプリケーション(ログライブラリ)、その他のアプリケーション&サーバー(ログファイル)、クバネティス(サービス)、AWSログ(CloudWatch Log、S3内のLog)を統合的に収集・分析。ログデータを素早く検索し、問題の根本原因を特定します。
ユーザーの目線から、WEBサイトへのアクセスと性能を定期的にチェックし、エラーなど問題点が現れたら各担当者へアラートを送ります。特定URLページの表示時間、エラーコードを常時監視。
クライアントブラウザのパフォーマンスをモニタリング。ページロード時間、リソース読み込み、JavaScriptエラーなど、エンドユーザーが体験する実際のパフォーマンスを計測・分析します。
ネットワークのパフォーマンスをリアルタイムで可視化し、遅延やパケットロスなどの問題を迅速に検出。通信経路全体のボトルネックを特定します。
ネットワークデバイスの稼働状態、トラフィック量、帯域使用率をリアルタイムで監視。ルーター、スイッチ、ファイアウォールなどのネットワーク機器を統合管理します。
Prometheus互換のOpenMetrics形式でメトリクスを収集し、WhaTapプラットフォーム上で統合的に分析・可視化。既存のモニタリング環境との連携が容易です。
WhaTap Application Monitoringならではの差別化ポイント
SQL、Http Callはもちろん、WhaTapの特許技術「アクティブスタック」で、煩わしいプロファイルの設定なしにMethodレベルまで追跡できます。
マイクロサービスアーキテクチャ(MSA)環境における、マルチトランザクションに対する連携追跡機能を提供します。全体のトランザクションを追跡して、どのアプリケーションから遅延が発生しているのかを確認できます。
トランザクションの詳細な動作履歴とトランザクションが実行される間に発生したログをまとめて確認できるため、問題個所をより簡単に把握できます。
アプリケーションのパフォーマンス区間の可視化により、問題点と原因を素早く見つけ出し改善できます。Hitmap、Active TX、TPS、応答時間をリアルタイムで表示。
システムの稼働状況やパフォーマンスをリアルタイムで見える化します。障害発生時、インフラの問題か、アプリの問題か、素早く解析可能な統合モニタリング環境を提供します。
トランザクションの応答時間の推移から障害パターンを自動検知し通知します。AI時代の運用複雑性を洞察するオブザーバビリティプラットフォームとして、異常の兆候を早期に発見し、障害の影響を最小化します。
過去の特定時間の性能データが簡単に確認でき、エラー発生や性能に異常があったボトルネックを容易に把握し、事後分析することができます。
AI時代の中核インフラであるGPUは、運用負荷の高いリソース。WhaTapなら、GPUリソース状況が可視化できます。GPUの使用率、メモリ、温度、消費電力をリアルタイムで把握し、AI/MLワークロードの最適化を支援します。
Application、Database、Server、Kubernetes、Log、URL、Browser、Network Performance、GPU、NMS、OpenMetricsの11種類のモニタリングを1つのプラットフォームで統合的に提供。GPUからアプリケーションまで全区間を網羅します。
AI時代の運用複雑性を洞察するオブザーバビリティプラットフォーム。障害パターンの自動検知と通知により、MTTR(平均復旧時間)を大幅に短縮します。
サーバー構築不要。エージェントをインストールするだけで、すぐにモニタリングを開始できます。15日間の無料トライアルで即座に効果を確認。
異常検知と対応にかかる時間・コストを大幅に短縮し、サービスレベル向上に貢献します。クラウド型なのでサーバ不要、必要な分だけ利用可能。
AWS、Azure、GCPなど主要クラウドプロバイダーに対応。オンプレミスとクラウドのハイブリッド環境もシームレスにモニタリング可能です。
日次/週次/月次のパフォーマンスレポートを自動生成。経営層への報告や監査対応にも活用できます。
Java、Node.js、PHP、Python、.NET、Golang
Oracle、PostgreSQL、EDB PAS、MySQL、MariaDB、Redis、MongoDB、MS SQL、AWS RDS、Tibero、Altibase、CUBRID
Windows、Linux(各ディストリビューション)、UNIX(FreeBSD)、x86ベース
Amazon EKS、Azure AKS、Google GKE、Oracle OKE、Red Hat OpenShift、Cocktail、Accordion、PaaS-TA
Javaアプリケーション(ログライブラリ)、サーバーログファイル、Kubernetesサービス、AWS CloudWatch Log、S3内ログ
AWS、Microsoft Azure、Google Cloud Platform(GCP)、Oracle Cloud、ハイブリッド/マルチクラウド環境
課題が明確でなくても大丈夫です。御社の状況をお聞かせいただければ、最適な解決策をご提案します。
資料請求・お問い合わせ